- KDD 2025論文のUMIモデルが提唱する「非合理性ファクター」を日本株約330銘柄で検証した
- ロングショート戦略の税前シャープレシオは1.01→2.34に大幅改善、ただし取引コスト後は両モデルともマイナス
- 予測精度(IC)の改善は統計的に有意ではなく、論文のIC+20%改善は日本株では再現できなかった

株価は本当に理屈どおりに動いているのか。「市場は常に合理的に動く」とする効率的市場仮説(EMH)は金融理論の土台になっている考え方だが、実際に売買していると、理屈では説明のつかない値動きにしょっちゅう出くわす。2025年、トップカンファレンスKDD(Knowledge Discovery and Data Mining)に採択された論文「UMI: Learning Universal Multi-level Market Irrationality Factors(Yang et al., KDD 2025)」は、この「市場の非合理性」を数値にして株価予測に使おうという大胆な提案をした。この記事では、論文の手法を日本株約330銘柄・13年分のデータで実際に試し、どこまで使えてどこに限界があるのかを確かめた。
1. 論文の概要と仮説
UMI論文(Yang et al., 2025)のアイデアの中心は「市場には理屈で説明できない値動きがあり、それを数値にすれば株価予測が良くなる」である。論文は、2つのレベルの「非合理性ファクター」を提案している。
銘柄レベルの非合理性(Stock-level Irrationality)
個別銘柄の株価は、本来、同じセクター(業種)の他の銘柄と似た動きをするはずである。たとえば半導体セクター全体が上昇しているときに、ファンダメンタルズ(業績や財務状況)に問題がないにもかかわらず下落している銘柄があれば、それは「非合理的な価格のずれ」と考えられる。
UMI論文では、この「セクター内での乖離(ずれ)」をニューラルネットワークで数値にする。具体的には、同じセクターの銘柄群の平均的な動きから、個別銘柄の動きがどれだけ離れているかを測る。離れ方が大きいほど「非合理性が高い」とみなし、株価がいずれ平均に戻る動き(平均への回帰)を予測する材料(特徴量)として使う。
市場レベルの非合理性(Market-level Irrationality)
もう一つの非合理性は、市場全体の同期性(多くの銘柄が同じ方向にそろって動く度合い)に関するものである。ふだんは、各銘柄がそれぞれの業績や財務にもとづいて動くので、全銘柄が同じ方向にそろうことは少ない。しかし、パニック的な売りやバブル的な買いが起きると、多くの銘柄が一斉に同じ方向へ動く。
UMI論文では、市場全体で銘柄間の動きがどの程度同期しているかをDCC-GARCH(動的条件付き相関GARCH)モデルなどで推定し、その同期度が高い場合を「市場レベルの非合理性が高い」と定義する。この指標は、群集心理による過剰反応やその後のリバーサル(反転)を予測するために使われる。
論文の主張するメリット
論文の検証では、米国市場と中国市場のデータを使っている。これらの非合理性ファクターをLSTM(Long Short-Term Memory、長短期記憶ネットワーク。時系列データの学習に適したニューラルネットワークの一種)などの予測モデルに追加すると、予測精度は10〜20%上がった。さらに、ロングショート戦略(予測上位を買い、下位を売る戦略)のシャープレシオ(リスクあたりのリターンを示す指標。1.0以上で優秀とされる)も20〜30%改善したと報告している。
2. データと検証手法
論文の手法を日本株で再現するため、以下のデータと条件で検証した。
| 項目 | 内容 |
|---|---|
| 対象銘柄 | TOPIX構成銘柄のうち、データが完備された約330銘柄(東証プライム市場中心) |
| 対象期間 | 2013年1月〜2026年4月(約13年間) |
| データ分割 | 訓練: 2013〜2019年 / 検証: 2020〜2021年 / テスト: 2022年〜2026年4月 |
| 入力特徴量 | OHLCV(始値・高値・安値・終値・出来高)の5項目を過去20営業日分 |
| 追加ファクター | 銘柄レベル非合理性(セクター内乖離)+ 市場レベル非合理性(銘柄間同期度) |
| 予測対象 | 翌営業日のリターン |
| モデル | LSTM(2層、隠れ次元64) |
| セクター分類 | 東証33業種をTOPIX-17相当にマッピング |
| 評価指標 | IC(情報係数)、RankIC(順位相関係数)、ロングショート戦略のリターン・シャープレシオ |
株価データは、自分で日次収集しているPostgreSQLの日本株データベースから取得した。2026年4月22日のノートブック実行時点で352銘柄・1,043,611行(2012年1月〜2026年4月)あり、ここから業種の対応が取れない銘柄や特徴量の欠損期間を除いて約330銘柄に絞っている。
3つのモデルの比較
検証では以下の3つのモデルを比較した。どのファクターが効いているのかを切り分けられるように、ファクターは1つずつ段階的に足している。
- Baseline LSTM: OHLCV(価格と出来高)のみを入力とする標準的なLSTMモデル
- + Stock irrationality only: Baselineに銘柄レベルの非合理性ファクター(セクター内乖離)のみを追加したモデル
- Enhanced LSTM(全ファクター): 銘柄レベル + 市場レベルの非合理性ファクターを両方追加した、論文のフルモデルに相当する構成
ファクター計算の核心部分は、検証ノートブックの以下のコードである。同じ業種の平均リターン(自分自身は除いて計算する)に対する感応度(ベータ)を過去60日で推定し、ベータで説明できない残差を「銘柄レベルの非合理性」として特徴量に加えている。
# セクター平均リターン(自銘柄を除いた平均)
daily['sector_ret_loo'] = (daily['sector_sum'] - daily['ret_1d']) \
/ (daily['sector_count'] - 1).clip(lower=1)
# 60日ローリングでセクター感応度betaを推定し、残差を非合理性とする
g['cov_60'] = g['ret_1d'].rolling(60).cov(g['sector_ret_loo'])
g['var_60'] = g['sector_ret_loo'].rolling(60).var()
g['beta_sector'] = (g['cov_60'] / g['var_60'].replace(0, np.nan)).clip(-3, 3)
g['stock_irr'] = g['ret_1d'] - g['beta_sector'] * g['sector_ret_loo']
g['stock_irr_abs_ma5'] = g['stock_irr'].abs().rolling(5).mean()評価指標の説明
IC(Information Coefficient、情報係数)とは、モデルの予測値と実際のリターンとのピアソン相関係数のことである。RankIC(Rank Information Coefficient)は予測値と実リターンの順位相関(スピアマン相関)で、外れ値の影響を受けにくい。いずれも値が大きいほど予測精度が高いことを意味し、一般に0.03〜0.05程度で「実用的に有意」、0.05以上で「良好」とされる。
データの前提条件と制約
今回の検証のデータと手法には以下の制約がある。結果はこの前提のうえで読んでほしい。
- 銘柄数の差異: 論文は米国約500銘柄・中国約300銘柄で検証しているが、今回は日本株約330銘柄である。銘柄数が少ないとセクター内の乖離計算が不安定になる可能性がある
- セクター分類の差異: 論文はGICS(世界産業分類基準)の11セクターを使用。今回は東証33業種をTOPIX-17に集約しており、セクター粒度が異なる
- 非合理性ファクターの近似計算: 論文のDCC-GARCHベースの市場同期度は計算コストが高いため、簡略化した銘柄間相関の集約値で代用している
- 生存者バイアス: 検証期間中に上場廃止となった銘柄は対象から除外されている
- 取引コスト: ロングショート戦略の実効性を評価するため、片道5bps(0.05%)の取引コストを仮定したネットリターンも算出した
3. 検証結果: 予測精度
まず、予測がどれだけ当たったかでモデルを比べる。テスト期間(2022年1月〜2026年4月)の各指標は以下のとおりである。
| モデル | 平均IC | 平均RankIC | IC正率 |
|---|---|---|---|
| Baseline LSTM(OHLCVのみ) | 0.0259 | -0.0085 | 55.9% |
| + 銘柄レベル非合理性のみ | 0.0316 | -0.0008 | 57.9% |
| Enhanced LSTM(全ファクター) | 0.0260 | -0.0006 | 55.1% |
結果を見て、気になった点が2つある。
まず、平均ICは3モデルとも0.025〜0.032の範囲に収まっており、差はごくわずかである。銘柄レベルの非合理性ファクターだけを足したモデルがいちばん高いIC(0.0316)を出したが、全ファクターを足したEnhancedモデルは0.0260と、Baselineとほぼ同じ水準に戻っている。市場レベルのファクターを足したことで、かえってノイズが増えたのかもしれない。
次に、RankICは全モデルでほぼゼロか、ごく小さいマイナスである。RankICがマイナスということは、予測の「順位付け」がほぼ当てずっぽうと変わらないことを意味する。ICがプラスでRankICがゼロ付近というのは、上がるか下がるかという大まかな方向はある程度当てられているが、「どの銘柄が他より良いか」の順位はほとんど当てられていない状態である。
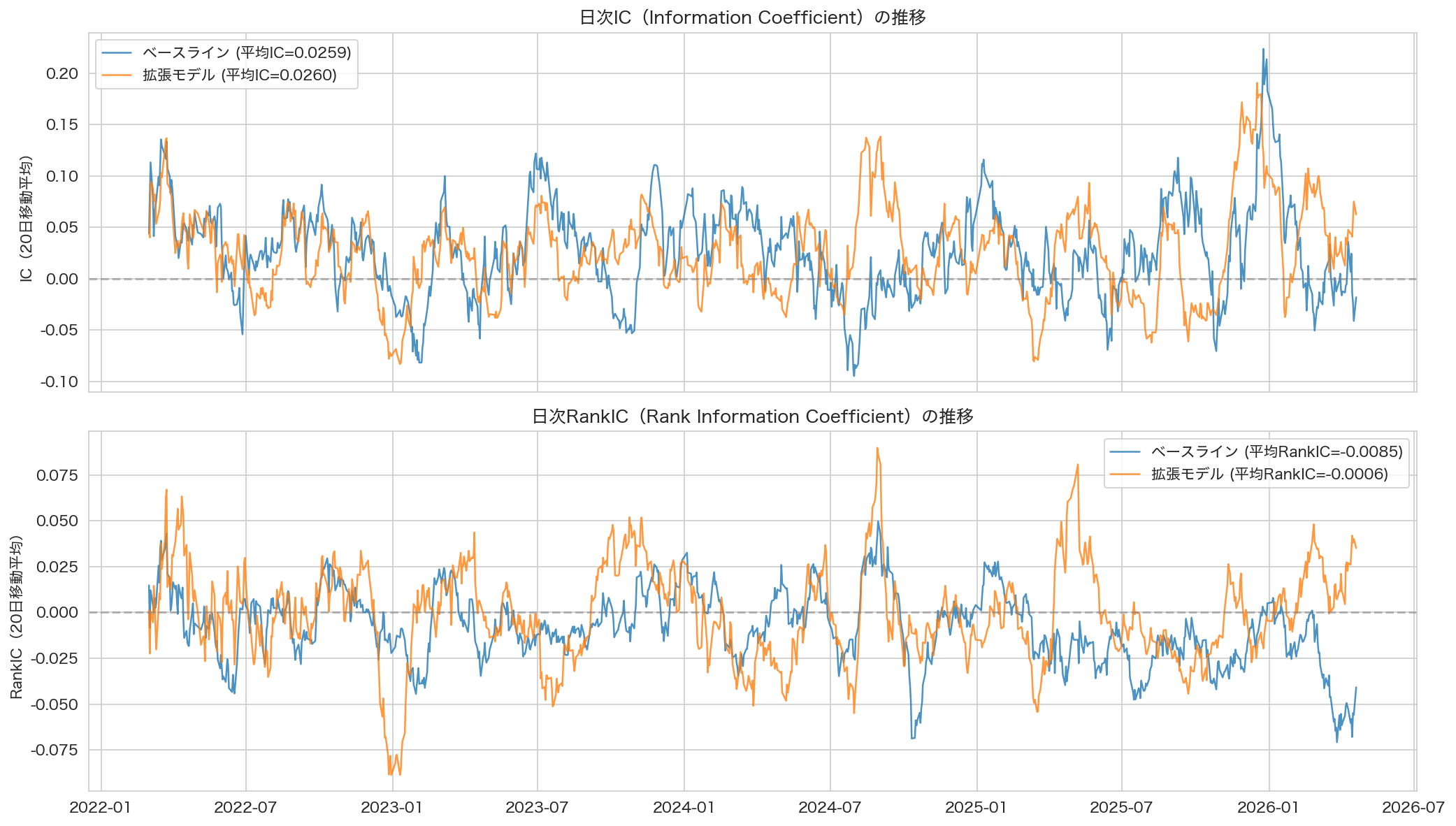
図1: テスト期間(2022年1月〜2026年4月)における日次ICの推移。青がBaseline LSTM、オレンジがEnhanced LSTM。両モデルともIC値の変動パターンはほぼ重なっており、ファクター追加による系統的な改善は視覚的に確認しにくい。
統計的検定の結果
ICの改善が統計的に有意かどうかを検定した結果は以下のとおりである。
IC改善のp値は0.998で、統計的に意味のある改善とは到底言えない。RankIC改善のp値は0.057で、5%の有意水準をわずかに上回る。統計の世界で「限界的に有意(marginally significant)」と呼ばれる、ぎりぎりの水準である。つまり、ファクター追加でRankICが良くなった可能性は捨てきれないが、自信を持って「効いた」と言える水準でもない。
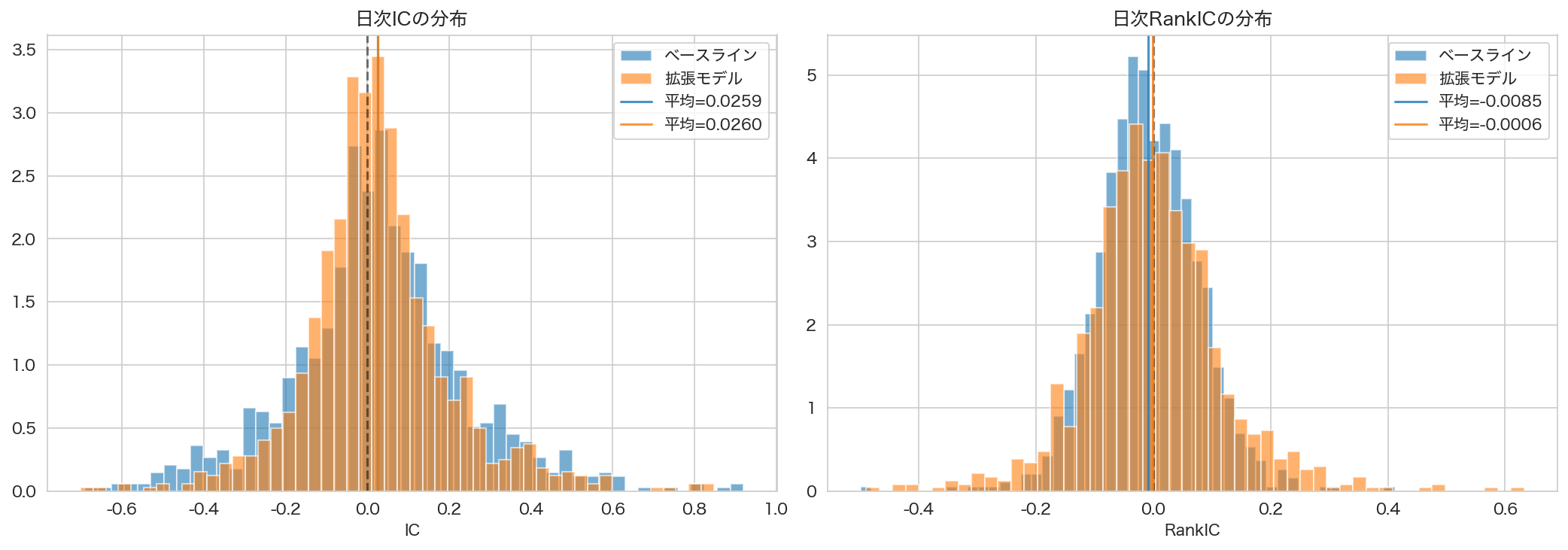
図2: 日次ICの分布。Baseline(青)とEnhanced(オレンジ)の分布形状はほぼ同一で、ファクター追加による分布のシフトは確認できない。両モデルとも分布の中心は0付近にあり、正のICを示す日がやや多い。
4. 検証結果: ロングショート戦略
予測精度の改善は限定的だった。次に、実際の投資戦略として使った場合の成績を確認する。各モデルの予測値に基づき、毎日上位20銘柄をロング(買い)、下位20銘柄をショート(空売り)するロングショート戦略のバックテスト結果を以下に示す。
| 指標 | Baseline | Enhanced | 変化 |
|---|---|---|---|
| 年率リターン(税前) | 10.4% | 25.8% | +15.4pt |
| シャープレシオ(税前) | 1.01 | 2.34 | +1.33 |
| 年率リターン(コスト後, 5bps) | -13.6% | -1.5% | +12.1pt |
| 最大ドローダウン | -54.5% | -28.4% | 改善 |
| 勝率 | 46.4% | 48.6% | +2.2pt |
税前の数字だけ見ると、正直驚くほど良い。Enhancedモデルのシャープレシオは2.34で、Baselineの1.01から大幅に改善した。年率リターンも10.4%から25.8%に伸びている。最大ドローダウンも54.5%から28.4%に改善しており、リスク管理の面でも優れている。
しかし、取引コストを入れた途端、結果はがらりと変わる。片道5bps(0.05%)という控えめなコストを仮定しても、Baselineは年率-13.6%、Enhancedでも-1.5%と、どちらもマイナスに転落する。毎日40銘柄を入れ替える戦略なので、そのたびに手数料が積み上がっていく。1日あたりの儲けが小さいため、手数料を払うだけで利益が消えてしまうのである。
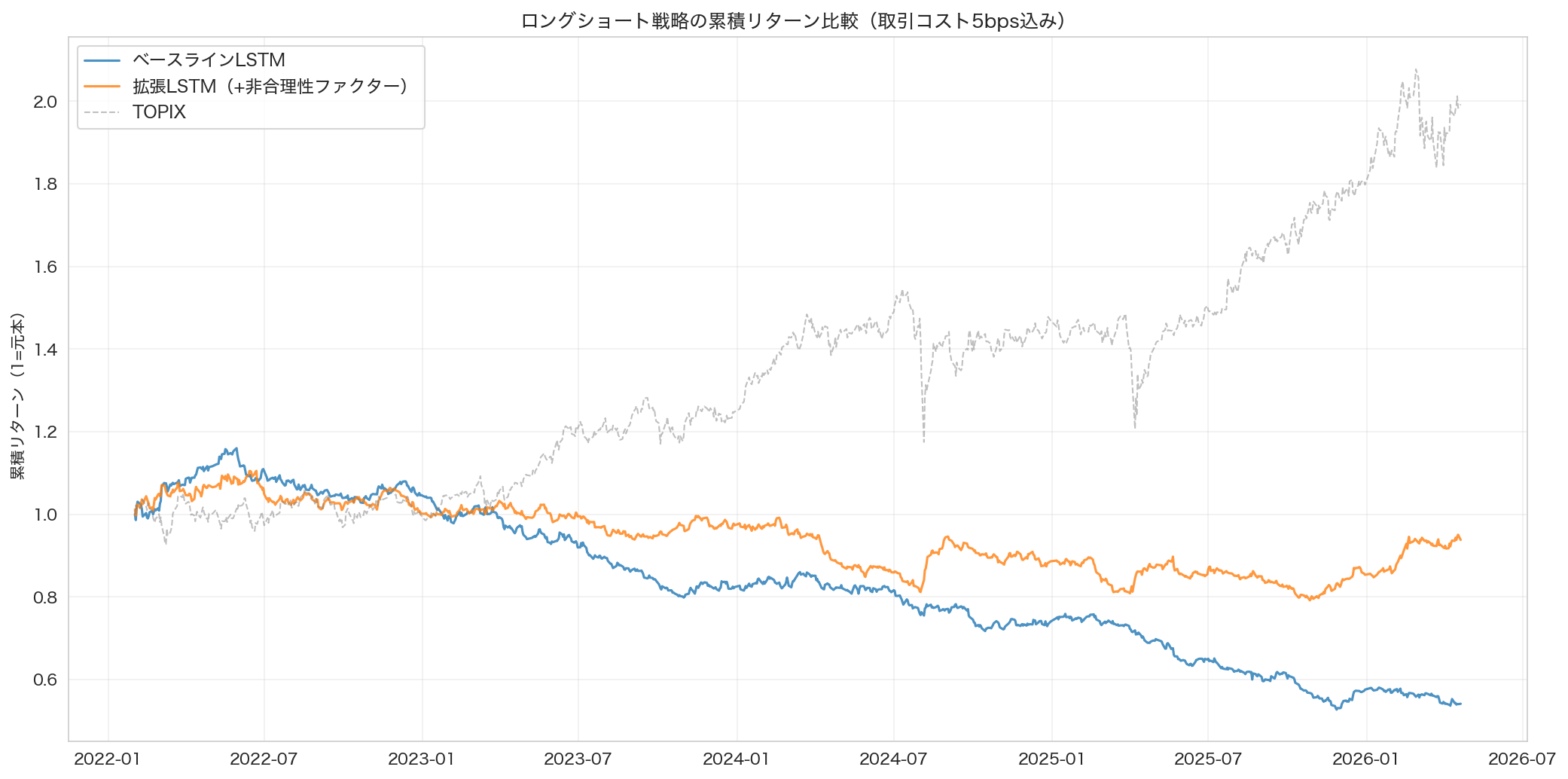
図3: ロングショート戦略の累積リターン推移。Enhanced LSTM(オレンジ)はBaseline(青)と比較して安定した右肩上がりを示すが、ネットリターン(取引コスト考慮後、破線)はどちらも横ばいからマイナス圏で推移している。
ICは横ばいなのにシャープレシオが改善した理由
ここで妙なことが起きている。予測精度(IC)はほぼ改善していないのに、戦略のシャープレシオは2倍以上に改善した。一見矛盾するこの結果がなぜ生じたのか、理由を考えてみた。
一番ありそうな説明はこうだ。ファクター追加は、予測全体の当たり具合(IC)ではなく、「極端な予測」の当たり具合を良くした。ロングショート戦略は予測値の上位と下位だけを使うので、予測の分布の両端(テール)が当たるかどうかが戦略の成績を大きく左右する。平均ICがほぼ同じでも、「大きく上がる(下がる)」と予測した銘柄の精度が上がっていれば、ロングショートのリターンは良くなりうる。
もう一つの可能性は、非合理性ファクターが「正則化」(モデルが過去のデータに合わせすぎる過学習を抑える働き)の役割を果たしたという説だ。予測のブレが減れば、リターンの上下動が小さくなり、シャープレシオは上がる。最大ドローダウンが54.5%から28.4%へ大きく改善している事実は、この説と合う。
5. 論文との比較と考察
今回の日本株での結果を、論文が報告した米国市場・中国市場の結果と比較する。
| 市場 | IC変化 | IC改善率 | シャープレシオ変化 | SR改善率 |
|---|---|---|---|---|
| 米国(論文) | 0.071 → 0.086 | +20% | 1.14 → 1.47 | +29% |
| 中国(論文) | 0.070 → 0.081 | +16% | 1.09 → 1.38 | +27% |
| 日本(今回) | 0.0259 → 0.0260 | +0.4% | 1.01 → 2.34 | +132% |
比較すると、大きな違いが2つある。
第一に、ICの改善率は日本株ではほぼゼロ(+0.4%)で、論文の+16〜20%とは大きく違う。しかもBaselineの時点でICの水準そのものが違い、日本株のIC(0.026)は米国・中国(0.070〜0.071)の約3分の1しかない。日本株は、価格と出来高のデータだけでは値動きを当てるのがそもそも難しいのだろう。
第二に、シャープレシオの改善率は日本株で+132%と飛び抜けて大きい。論文の+27〜29%を大きく上回る。ただし前に書いたとおり、これは「極端な予測の当たり具合」や「予測の安定性」が良くなったためで、ICの改善とは別の理由で起きている可能性が高い。取引コストを引けばどちらもマイナスという点も変わらない。
日本株でICが改善しなかった理由
日本株でICが改善しなかった原因は、次のあたりにあると考えている。
- セクター構造の違い: 米国市場はGAFAMのような巨大テック企業の存在感が大きく、同じセクターの銘柄がそろって動きやすい。一方、日本市場は製造業の比率が高く、同じセクターでも銘柄ごとの動きがばらばらになりやすい。セクター乖離ファクターは「同じセクターなら似た動きをする」ことが前提なので、日本では効きにくいのかもしれない
- 市場参加者の違い: 中国市場は個人投資家の比率が高く(約60%)、群集心理による非合理的な動きが出やすい。米国も小型株を中心に同じ傾向がある。日本市場の個人投資家比率は約20%で、機関投資家が中心のぶん、価格は比較的理屈どおりに決まりやすい。「非合理性」そのものが小さければ、それをとらえるファクターの効果も小さくなる
- 近似計算の限界: 今回はDCC-GARCHベースの市場同期度を簡略化した計算で代用したため、論文と同じ精度でファクターを作れていない可能性がある。とくに市場レベルの非合理性ファクターは、全ファクターモデルでICが下がった一因かもしれない
シャープレシオ2.34をどう受け止めるか
この論文のアイデア自体は面白い。「市場の非合理性を数値にして予測に使う」という枠組みは、行動ファイナンス(投資家の心理のクセを研究する分野)の研究成果を、アルファ(市場平均を上回る超過リターン)を取りにいく道具に直結させる発想で、理屈の筋は通っている。
しかし、日本株での検証結果は「ICの改善なし」「取引コスト後はマイナス」で、個人投資家がそのまま使える内容ではなかった。特に引っかかるのは、ICが改善していないのにシャープレシオが大幅改善したという矛盾だ。この結果はファクターの「正則化効果」で説明できるが、それは「非合理性を予測に使っている」という論文の主張とは別の仕組みである。
もう一つ気になる点がある。日本株はそもそも予測しにくい。BaselineのICが0.026という水準は、米国・中国の3分の1であり、OHLCVだけでは日本株のリターンをほとんど予測できていない。この「予測の土台」が弱い状態では、どんなに優れたファクターを追加しても大幅な改善は期待しにくい。日本株で機械学習ベースの予測をやるなら、OHLCVに加えてファンダメンタルズデータ(財務指標、アナリスト予想など)や需給データ(信用残、投資主体別売買動向など)を入力に足すほうが効くと見ている。土台の予測力そのものを引き上げるほうが先だ。
6. まとめ
結論: アイデアは有望だが、日本株での実用化にはハードルが残る
- UMI論文の「非合理性ファクター」を日本株330銘柄で検証した結果、予測精度(IC)の改善は統計的に有意ではなかった(p=0.998)
- ロングショート戦略のシャープレシオは1.01→2.34と大幅改善したが、取引コスト後は-1.5%のマイナスであり、手数料で利益が消えるため毎日リバランスするやり方ではそのまま使えない
- 論文が報告したIC+16〜20%の改善は日本株では再現できず、その背景にはセクター構造の違い、市場参加者構成の違い、予測ベースラインの低さがある
- ただし、最大ドローダウンの改善(54.5%→28.4%)やシャープレシオの向上を見ると、ファクターは「予測精度」ではなく「予測の安定性」を良くしている可能性がある。この点はさらに調べる価値がある
今後の展望
今回の検証は「論文の再現」を優先したので、改善の余地はまだ多い。次に試すなら、このあたりだと考えている。
- リバランス頻度の低減: 日次ではなく週次・月次のリバランスに変更し、取引コストを抑える
- 入力特徴量の拡充: OHLCVに財務データや需給データを足し、ベースラインのIC自体を引き上げる
- DCC-GARCHの完全実装: 市場同期度の計算を論文どおりに実装し、近似で精度が落ちた影響を取り除く
- 個別セクターの効果検証: どのセクターで非合理性ファクターが効いているかを調べ、効くセクターに絞ってファクターを使う
学術論文の手法がそのまま利益につながることはめったにない。それでも、論文のアイデアを出発点に、日本市場の性質に合わせて作り替えていけば、実際に使える戦略にたどり着ける可能性は十分あると見ている。
※本記事は公開情報に基づく情報整理であり、個人の見解を含みます。特定の銘柄の売買や投資を推奨するものではありません。投資判断はご自身の責任においてお願いいたします。